Clipping, also known as saturation, is a common phenomenon leading to sometimes seriously distorted audio recordings. Declipping consists in performing the inverse process, to restore saturated audio recordings and improve their quality. A-SPADE is a declipping algorithm developed by PANAMA (a joint project-team between Inria and CNRS). It is based on on the expression of declipping as a linear inverse problem and the use of analysis sparse regularization in the time-frequency domain.
To the best of our knowledge SPADE achieves state-of-the-art declipping quality.
For more information, please visit this website: spade.inria.fr. You can also contact us through this form.
Before using the software, have a look at this documentation and at the “Demo” tab
which provides some input examples (parameters and audio files)
that can be used with A-SPADE. The “Demo” tab also provides output
examples.
Usage
A-SPADE will give you the desaturated version of your input signal as a .wav file.
Supported input formats are .wav, .mp3, .mp4, .m4a, .ogg, .flac. Long multi-channel files are eligible for declipping.
This online application, as a trial version of the software with limited parameters options, will process only the first 2 channels if the audio file duration is less than 20 minutes.
If you are interested in processing longer excerpts or more than stereophonic recordings, please contact us.
To use the software, follow these steps:
Upload your audio file(s) with the “+ Upload File” button.
a mandatory clipped input file;
an optional clean reference (Warning: If you have a clean reference make sure that it is recorded with the same sampling rate as the saturated one, that it has the same channel number and the same duration but a different name).
In the “Version” pop-up menu, check that the latest software version is selected.
Fill the “Parameters” section with a list of option (in any order):
Mandatory option:
-c clippedfilename: You have to provide the name of the clipped file;
Optional: the other parameters:
-d declippedfilename: The name of the declipped (output) file;
-p preset: One preset allowing some tuning of the algorithm: “highQuality”, “average”, “fastest” (default value);
Start your declipping by clicking on the “Run this job” button.
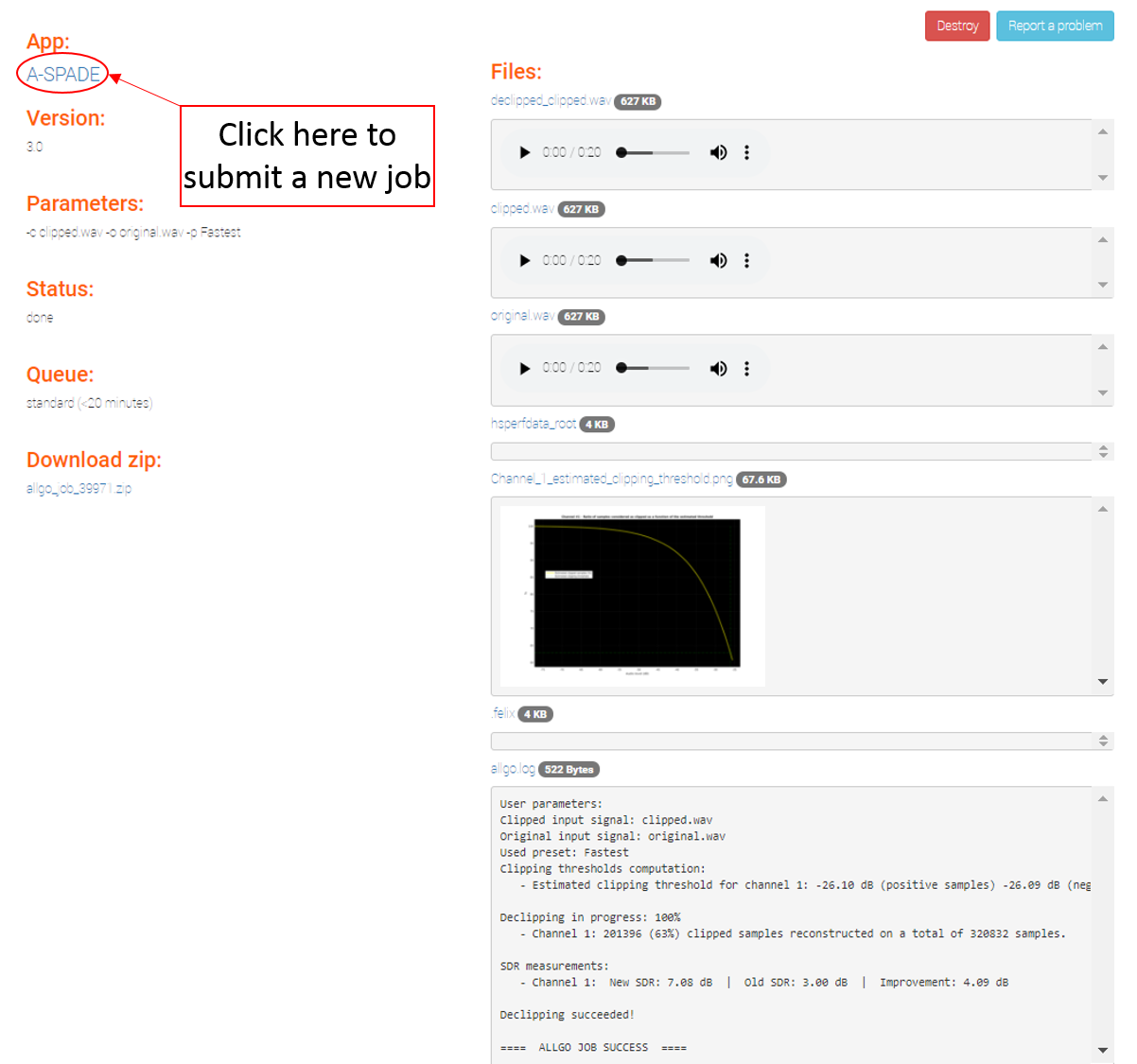
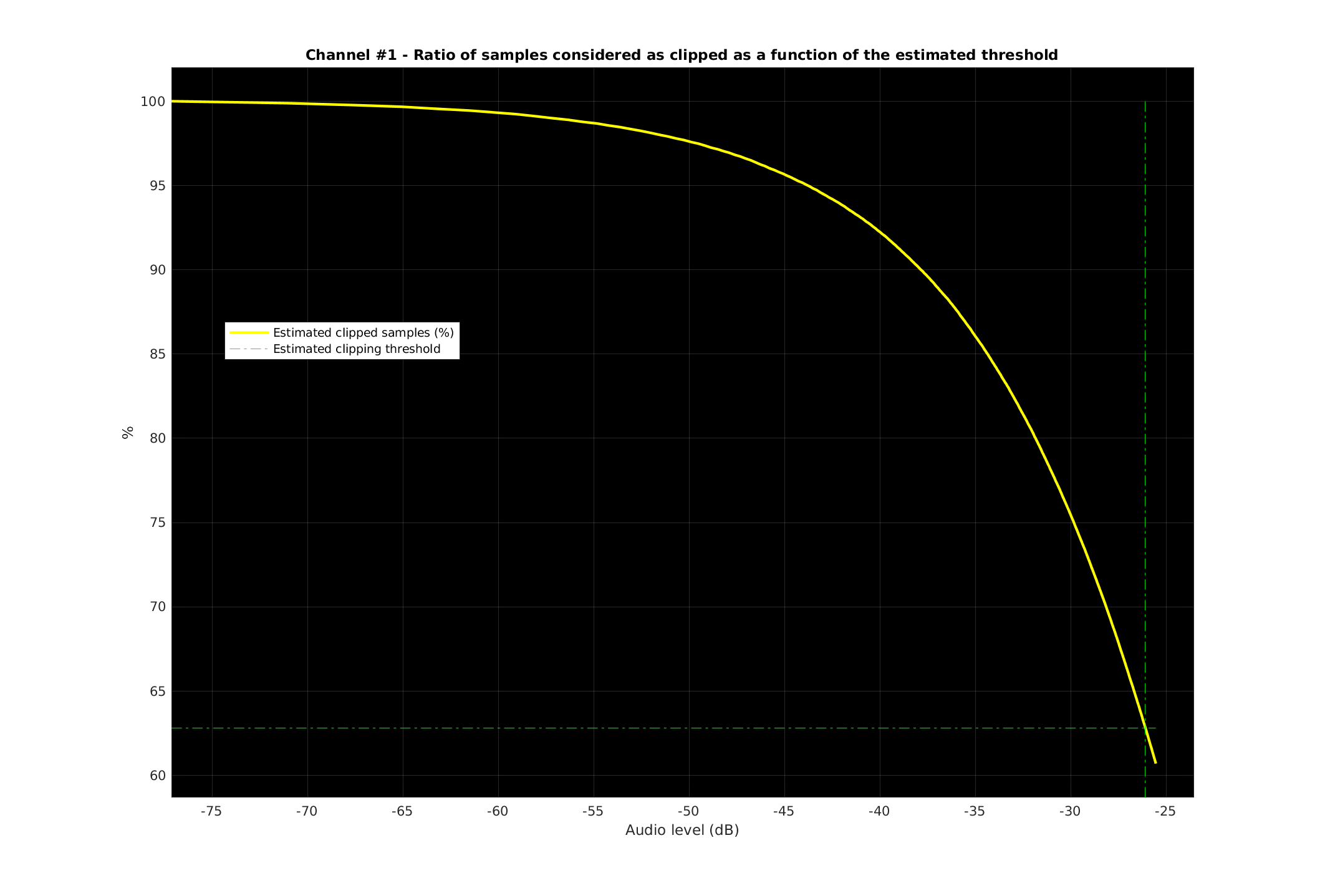
Once your job is finished you should be able to listen to the result and save your declipped signal in a file named “Declipped_<name of your input file>.wav”. As in the screenshot below, if you provided a reference signal you will get the SDR (Signal to Distortion Ration in dB) measurements before and after processing in the “allgo.log” file. Finally, you will find, for each channel, an overview of the ratio of clipped samples for the computed clipping threshold.
To try the application with other files and submit a new job, click on the “A-SPADE” link in the left top corner of the result page as shown below.
Processing time
The processing time depends on the chosen preset (“fastest”, “average”, “highQuality”) and increases with:
the number of clipped samples;
the sampling frequency;
the file duration;
the number of channels.
Once the job is running, it could take from a few seconds to a few minutes to get the declipped version of your file.
Licence and Credits
You may exploit this software for a non-commercial scientific purpose
provided you mention it in any written work or software you derive from
its use. Within a published article, paper or report, the software must
appear in the bibliographical references as:
S. Kitic, N. Bertin and R.Gribonval. Sparsity and cosparsity for audio
declipping: a flexible non-convex approach. In Latent Variable Analysis
and Signal Separation, Liberec, 2015.
The examples shown in the "Demo" section are from the RWC Jazz Database:
M. Goto, H. Hashiguchi, T. Nishimura, and R. Oka: RWC Music Database: Popular, Classical, and Jazz Music Databases In Proceedings of the 3rd International Conference on Music Information Retrieval (ISMIR 2002), 2002.
User parameters:
Clipped input signal: clipped.wav
Original input signal: original.wav
Used preset: Fastest
Clipping thresholds computation:
- Estimated clipping threshold for channel 1: -26.10 dB (positive samples) -26.09 dB (negative samples)
Declipping in progress: 100%
- Channel 1: 201396 (63%) clipped samples reconstructed on a total of 320832 samples.
SDR measurements:
- Channel 1: New SDR: 7.08 dB | Old SDR: 3.00 dB | Improvement: 4.09 dB
Declipping succeeded!
==== ALLGO JOB SUCCESS ====
13/11/2024 : Version 3.3, extend first 30 seconds to 20 minutes
21/06/2024 : Version 3.2.1, extend first 30 seconds to 20 minutes
13/08/2018 : Version 3.2, Solve issue with .m4a files
06/08/2018 : Version 3.0, New algorithm to compute clipped thresholds. Processing time reduction.
08/03/2018 : Version 2.0,
16/01/2018 : Version 1.5,
21/12/2017 : Version 1.4,
26/04/2017 : Version 1.3,
22/03/2017 : Version 1.2,
28/02/2017 : Version 1.1,
06/10/2016 : Version 1.0,
How to use our REST API :
Think to check your private token in your account first.You can find more detail in our documentation tab.
This app id is : 134
This curl command will create a job, and return your job url, and also the average execution time
files and/or dataset are optionnal, think to remove them if not wanted