SAMuSA detects the segments of speech, music and silence within your audio and audio-visual documents.
Overview:
This service analyzes the audio stream using the SPro software for feature extraction [1] and external audio HMM class models. The segmentation and classification steps are then realized using Viterbi decoding implemented in the Audioseg software [2]. Trained on hours of various TV and radio programs, this service provides efficient results: 95% of speech and 90% of music are correctly detected. One hour of audio can be computed in approximately one minute on standard computers.
References:
[1] SPro through Inria GForge
[2] Audioseg through Inria GForge
(Version 1.0 of this web service includes SPro v5.0 and Audioseg v1.2.2)
File formats:
SAMuSA takes the audio stream from audio or video files as input, and outputs the music/speech segmentation in raw text and JSON formats. A JSON file produced by other multimedia services from A||go can be provided as input to be completed with this segmentation.
- inputs:
-
audio file: many formats are supported (wav, mp3, ogg, flac, MP4...) as the entry is converted to a 16bits 16kHz mono wav file using ffmpeg.
-
JSON file (optional): uploading the JSON output "<audio_file_name>.json" from A||go's multimedia webservices leads to its update with SAMuSA's results under the 'samusa' label, along with metadata from the audio stream.
- outputs:
-
JSON file with the following format:
{
"general_info":{
"src":"<input_file_name>",
"audio":{
"duration":"<time_in_hh:mm:ss_format>",
"start":"<temporal_offset_in_seconds>",
"format":"<bit_coding_format>",
"sampling_rate":"<frequency> Hz",
"nb_channels":"<n> channels",
"bit_rate":"<bit_rate> kb/s"
}
},
"samusa":{
"annotation_type":"speech/music segments",
"system":"samusa",
"parameters":"<input_parameters>",
"modality":"audio",
"time_unit":"seconds",
"events":[
{
"start":<seg_start_time>,
"end":<seg_end_time>,
"type":"<class_name>",
"confidence": <log-likelihood_score>
},
{
"start":<seg_start_time>,
"end":<seg_end_time>,
"type":"<class_name>",
"confidence": <log-likelihood_score>
},
...
{
"start":<start_time>,
"end":<end_time>,
"type":"<class_name>",
"confidence": <log-likelihood_score>
}
]
}
}
with <start_time> and <end_time> in seconds. <class_name> can be "music", "speech", "oth" (other) and their combinations. SAMuSA also uses a "sil" (silence) class, but please use the SilAD service for a more accurate detection of silences.
Parameter:
-p: inter-class penalty used in the Viterbi decoding (default value is 100).
Demonstration video:
https://www.youtube.com/watch?v=CB4V71ngZu4
Credits and license:
SAMuSA was developed by Frédéric Bimbot, Guillaume Gravier and Olivier Le Blouch in Irisa/Inria Rennes Bretagne Atlantique. It is the property of CNRS and Inria. SAMuSA is currently available as a prototype which can be released and supplied under license on a case-by-case basis. Spro was developed by Guillaume Gravier. AudioSeg was developed by Mathieu Ben, Michaël Betser and Guillaume Gravier.
In input :
In output :
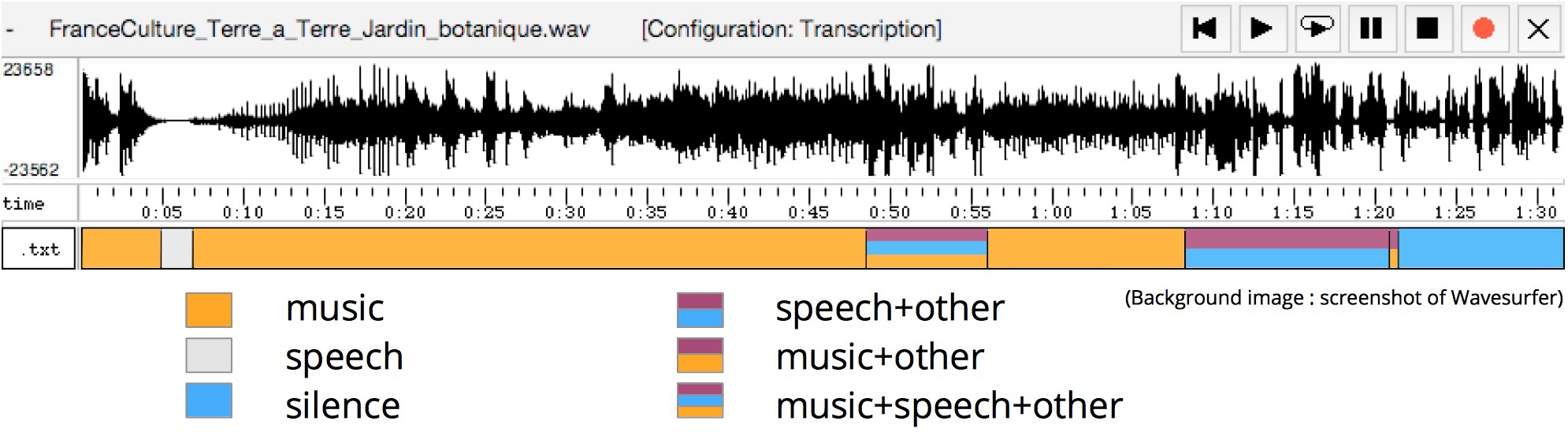
FranceCulture_Terre_a_Terre_Jardin_botanique_samusa.txt
music 0.00000 4.87000 -1.979488e+03
sil 4.87000 6.83000 -3.753783e+01
music 6.83000 48.46000 -4.094062e+04
music+speech+oth 48.46000 55.98000 -7.873867e+03
music 55.98000 68.20000 -1.414029e+04
speech+oth 68.20000 80.90000 -8.765133e+03
music+oth 80.90000 81.40000 -5.661647e+02
speech 81.40000 91.74000 -4.422663e+03
Samusa_example.jpg
04/08/2017 : Version 1.0,
How to use our REST API :
Think to check your private token in your account first.
You can find more detail in our documentation tab.
This app id is : 1
This curl command will create a job, and return your job url, and also the average execution time
files and/or dataset are optionnal, think to remove them if not wanted
curl -H 'Authorization: Token token=<your_private_token>' -X POST
-F job[webapp_id]=1
-F job[param]=""
-F job[queue]=standard
-F files[0]=@test.txt
-F files[1]=@test2.csv
-F job[file_url]=<my_file_url>
-F job[dataset]=<my_dataset_name> https://allgo.inria.fr/api/v1/jobs
Then, check your job to get the url files with :
curl -H 'Authorization: Token token=<your_private_token>' -X GET https://allgo.inria.fr/api/v1/jobs/<job_id>
