SilAD detects segments of silence and audio activity within an audio file or a video file.
Overview:
This service divides the input audio signal into short frames and calculates their energy. The distribution of energies is assumed to be a two-Gaussian distribution: the Gaussian with the smallest mean models silence frames while the other models audio activity frames. All the frames of the audio signal are classified as silent ('sil') or active ('speech') using this two-Gaussian model, using either a maximum likelihood classification or a threshold depending on the average energy of the activity Gaussian.
The content of active segments can be precised in terms of music and speech by adding the output file of A||GO's Samusa service obtained for the same audio input.
File formats:
SilAD takes the audio stream from audio or video files as input and outputs the audio activity/silence segmentation within two file formats: raw text and JSON.
- inputs:
- audio/video file: many formats are supported (wav, mp3, ogg, flac, MP4...) as the input audio track is converted to a 16bits 16kHz mono wav file using FFMPEG.
- JSON file (optional): uploading the JSON output "<audio_file_name>.json" from A||go's multimedia webservices leads to its update with SilAD's results under the 'silad' label, along with metadata from the audio stream. If it contains the music/speech segmentation from SAMuSA for the same audio file ('samusa' label), it is enhanced with Silad's silent segments under the 'samusa+silad' label. In this case, the 'samusa' label and its informations are removed from the JSON file, and no 'silad' label is added.
- outputs:
- text file: "<input_file_name>_silad.txt" is made of three columns following the format below:
<class_name>\t<start_time>\t<end_time>\n
<class_name>\t<start_time>\t<end_time>\n
...
each line describing a single segment. <start_time> and <end_time> are expressed in seconds
- JSON file with the following format:
{
"general_info":{
"src":"<input_file_name>",
"audio":{
"duration":"<time_in_hh:mm:ss_format>",
"start":"<temporal_offset_in_seconds>",
"format":"<bit_coding_format>",
"sampling_rate":"<frequency> Hz",
"nb_channels":"<n> channels",
"bit_rate":"<bit_rate> kb/s"
}
},
"silad":{
"annotation_type":"silence/signal activity segments",
"system":"silad",
"parameters":"<input_parameters>",
"modality":"audio",
"time_unit":"seconds",
"events":[
{
"start":<seg_start_time>,
"end":<seg_end_time>,
"type":"<class_name>"
},
{
"start":<seg_start_time>,
"end":<seg_end_time>,
"type":"<class_name>"
},
...
{
"start":<start_time>,
"end":<end_time>,
"type":"<class_name>"
}
]
}
}
each element of the "events" list being a particular segment. Note that the "system" tag will be associated to "samusa+silad" instead of "silad" if the silence/activity detection is fused with the output from SAMuSA. <start_time> and <end_time> are expressed in seconds
Parameters:
-m: value of the minimal duration of 'silence' segments in seconds (default value = 0.5 s). This parameter can be adjusted to avoid over-segmentation problems due to the processing at the frame-level.
-e: value of the parameter adjusting the threshold between the 'active' and 'silent' classes assigned to the audio frames. The threshold is the mean of the Gaussian modeling 'active' frames shifted by a fraction (= the entered value) of the standard deviation. By default, the classification of frames is performed by a Maximum Likelihood classifier.
Credits and license:
SilAD is the online version of SSAD, a module of the Audio Segmentation (AudioSeg) Toolkit. AudioSeg was developed by Mathieu Ben, Michaël Betser and Guillaume Gravier in Irisa/Inria Rennes Bretagne Atlantique. AudioSeg is the property of CNRS and Inria and is available under the GNU General Public Licence v.2 (June 1991).
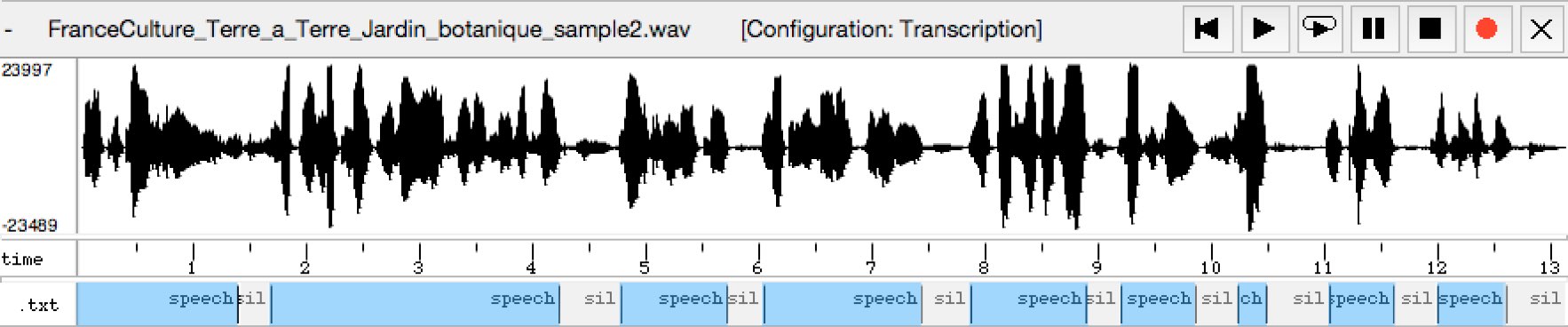
In input :
In output :
FranceCulture_Terre_a_Terre_Jardin_botanique_sample2_silad_with_"-m 0.25".txt
speech 0.00000 1.39000
sil 1.39000 1.68000
speech 1.68000 4.24000
sil 4.24000 4.78000
speech 4.78000 5.72000
sil 5.72000 6.04000
speech 6.04000 7.44000
sil 7.44000 7.88000
speech 7.88000 8.89000
sil 8.89000 9.20000
speech 9.20000 9.86000
sil 9.86000 10.23000
speech 10.23000 10.49000
sil 10.49000 11.04000
speech 11.04000 11.61000
sil 11.61000 12.00000
speech 12.00000 12.60000
sil 12.60000 13.14000
SilAD_example.jpg
22/01/2016 : Version 1.0,
How to use our REST API :
Think to check your private token in your account first.
You can find more detail in our documentation tab.
This app id is : 73
This curl command will create a job, and return your job url, and also the average execution time
files and/or dataset are optionnal, think to remove them if not wanted
curl -H 'Authorization: Token token=<your_private_token>' -X POST
-F job[webapp_id]=73
-F job[param]=""
-F job[queue]=standard
-F files[0]=@test.txt
-F files[1]=@test2.csv
-F job[file_url]=<my_file_url>
-F job[dataset]=<my_dataset_name> https://allgo.inria.fr/api/v1/jobs
Then, check your job to get the url files with :
curl -H 'Authorization: Token token=<your_private_token>' -X GET https://allgo.inria.fr/api/v1/jobs/<job_id>